Beginner’s guide to Tasker, part 4: Variable data processing

With the basics, variables (in general), and scenes now all covered, it’s time to dig into something a bit more specific: Processing data using Tasker variables. It’s more of an implied feature than the previous topics, but it’s also (in my opinion) one of the most powerful features in Tasker.

Variable data processing?
I’m kinda making up terms here, but it’s as good a term for this aspect of Tasker as anything. By variable data processing, I’m referring to how you can work with data stored in variables, extracting information from it, creating your own contexts, and so on and so forth. I have multiple profiles and tasks that use this in my Tasker, and some of them have been posted on this site before. The calendar event announcer and the weather forecast announcement system are both examples of variable data processing. It’s all about taking some data – text, in other words – and working on it until you get what you need from it.
Data sources
To really understand the power of variable data processing you first have to realize how many potential data sources there are out there. More or less anything that is stored in text form can be used in Tasker, it’s all about knowing how. Websites, exported calendar data, text documents – all of them are potential data sources. If you see some text, you can most likely use it in Tasker – it’s that simple. Weather data, local news, moon phases, horoscopes, Pocketables articles, you name it. Want to create a profile that is active when your horoscope mentions money? No problem.
It’s also important to understand the difference between what you see and what a computer sees. A web page is seen by the computer as pure text, a mixture of references to images, text, rules for how to lay out the page, and so on. CTRL + U brings up the page source of a web page in most web browsers, allowing you to see what the computer sees – the web page in pure text form. The chaos of text that greets you when you look at the source can be frightening at first, but as you’ll see further down, it can also be extremely useful.
Reading data into variables
The first part of any system based on outside data sources is to get the data into a variable, where we can work with it. There are many ways of doing this, but some of the most important ones are Read File, HTTP Get, Get Voice, and Variable Query – all of which are actions. The examples will focus on data gathered with HTTP Get though, as that’s the hardest to work with, and the most powerful.
- Read File reads a file stored on the internal memory into a variable, like the contents of a text file.
- HTTP Get is used to get (the source text of) a webpage into a variable, %HTTPD.
- Get Voice is used to listen for voice input, which is then turned into text and stored in a variable, %VOICE. This is the foundation for a DIY voice assistant like my Nelly.
- Variable Query pops up a dialog box asking for a variable value. Great for things like quick todo list entries, Tasker-based accounting systems, URL archive, and so on.
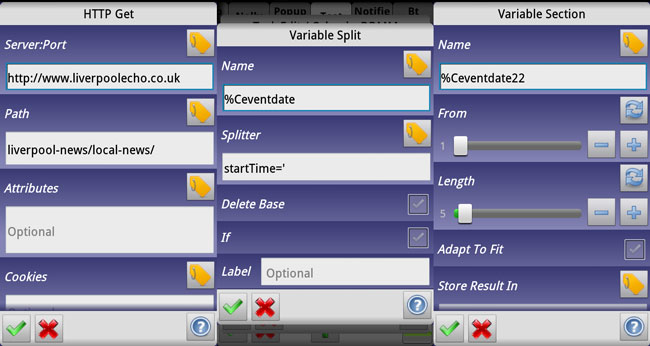
HTTP Get
HTTP Get (found in the Net action category) is perhaps the most versatile data collection action of them all, as it allows you to load web pages into variables. It does however have some quirks here and there. In theory, it loads the contents of the web page into the built-in variable %HTTPD. On some devices however, like mine, %HTTPD simply doesn’t contain the right data (or any data) after using HTTP Get. In such cases, using HTTP Get’s option to save to a file, combined with Read File to get it into a variable, is an excellent workaround. In examples further down you’ll see this approach a lot, though I should point out that simply using HTTP Get to populate the built in %HTTPD variable is the “proper” way to do things – when it works. Then again, to actually work with the data you have to have it in a user created variable, meaning you have to copy the contents of %HTTPD to another variable, leaving you with just as many actions as if you use HTTP Get and Read File.
In the HTTP Get configuration screen, you’ll see several fields, the top two being Server:Port and Path. As a general rule, put anything before and including the domain (like .com) in the first field, and the rest in the Path field. For instance, the URL
Would be split into these two fields:
Server:Port: http://pocketables.com
Path: 2012/09/beginners-guide-to-tasker-part-3-scenes.html
In theory, the contents of this URL should then be available in %HTTPD after the actions runs. If not, use the Output File field to save it to a file (e.g. pocketables.txt) and then use Read File on that file.
Data processing tools
Once you get the data into a variable, the job of actually turning it into something useful begins. Often, especially if you load entire web pages into a variable, the variable becomes an epic mess of text. It’s always a good idea to do this type of Tasker setup in front of a computer, so that you can have the full text available in front of you. If you’re working with a web page, for instance, have the source code (CTRL + U) of the page in front of you to get a better look at what is in the Tasker variable. You’ll see me do this in the video in example 2.
Next up I’ll cover some of the most common tools you’ll be using when working with the data. These are all actions that manipulate the content of a variable, and as such, are located in the Variable action category. I won’t cover all, but I will cover the most important ones.
Variable Split
 Congratulations, you just met the single most important action there is for this kind of Tasker setup. Variable Split could just as well be called Variable Chainsaw or Variable Ninjasword, as what it does is that it cuts/slices variables into pieces. It has two relatively simple configuration fields: Name and Splitter. Name is the name of the variable you want to chop into pieces, and Splitter can best be described as the point in the variable where you want to split it.
Congratulations, you just met the single most important action there is for this kind of Tasker setup. Variable Split could just as well be called Variable Chainsaw or Variable Ninjasword, as what it does is that it cuts/slices variables into pieces. It has two relatively simple configuration fields: Name and Splitter. Name is the name of the variable you want to chop into pieces, and Splitter can best be described as the point in the variable where you want to split it.
For instance, let’s say you have a variable %Hobbies that contains the text “football,hockey,swimming”
If you then use a comma (,) as the splitter, the “chainsaw” will target all of the commas and cut the variable in those spots. The actual splitters will be destroyed in the process. This creates new variables that are numbered derivatives of the original, each containing a piece. In this case, you would get the following variables:
%Hobbies1: football
%Hobbies2: hockey
%Hobbies3: swimming
You just used the commas as points to split a single variable into smaller, individual pieces. This method is the alpha and omega of variable data processing. By choosing the right splitters you can chop huge variables containing entire web pages into small, manageable pieces that contain just the information you need. You can split a weather website into variables that contain just the weather forecast, or split a news site into just the titles.
This is where all the “weird” text in a web page comes in handy. All the tags that are used to assign formatting to specific parts of a web page can very often be used as splitters as well, allowing you to grab parts of a web page much more easily than you’d think from seeing just the text. By using the source on a computer together with CTRL + F (find text on page), you can feel your way to finding a good splitter.
As an example, let’s take a look at pocketables.com. Let’s say that we want to create a list of articles currently on the front page, both links and titles. We load the page into the variable %Pocketables. Looking at the source in a browser (which is also what’s in %Pocketables at this point), we see how each article is listed in the source code:

All the tags (like <h3>) in between the text are what decides how the page looks to you – it’s like a guide for telling the browser how to display the page. You see the visual result, but Tasker sees this code when you load a web page into a variable like this. This is a good thing, as we can use these tags as splitters.
In this case, we see that the link to each article is immediately preceded by <h3><a href=”. By using CTRL + F in a full browser and searching for <h3><a href=” in the source, we see that there are only 10 occurrences, which means it’s only used before each of the ten articles on the front page. If there were 20, we could assume that it was used twice for each article. If there were 175, we could assume that it was used all over the place. We want the splitter to be as exclusive as possible, and in this case, <h3><a href=” would give us 11 “child” variables (as the first child variable would contain what’s before the first occurrence of the splitter, hence giving us one child more than there are splitter occurences).
%Pocketables4 would then for instance contain all the text between <h3><a href=” number 4 and <h3><a href=” number 5. As you can see from the image above, this is still a lot more text than what we want:

However, as you can see, the URL is immediately followed by ” title=”. This means that if we split each child variable again using this splitter, the first of the second generation child variables will contain the URL, and only the URL. An example of such a variable would be %Pocketables41. This is not the 41st child variable, but rather the first child of the %Pocketables4 variable.
%Pocketables42 will then contain everything following ” title=” up until the end of the original %Pocketables4. This variable starts with the title of the article, and then has lots of “garbage” at the end. Using the same method as we did to get the URL by itself we split %Pocketables42 using the splitter “>, which is the text immediately following the title. We’re then left with a third generation child, %Pocketables421, which contains just the title of the article.
To summarize, here’s a code snippet with relevant parts highlighted. The three pieces of red text are the various splitters used, blue is the second generation child (%Pocketables41 in the example), and purple/pink is the third generation child (%Pocketables421). The text at the end is just a shortened version of all the garbage that we cut away.
<h3><a href=”http://pocketables.com/2012/09/tv-show-favs-for-android-hits-version-3-0.html” title=”TV Show Favs for Android hits version 3.0“>TV Show Favs for Android hits version 3.0</a></h3>
By using this simple splitting method, you can chop up data into the chunks you need. You here have two variables that can be used directly elsewhere, for instance you could have a Open URL action with %Pocketables41 in the URL field and a Say action with %Pocketables421 in the text field, and have Tasker open a URL while speaking the title of the page it’s opening.
In this case, you would need to do this splitting process 10 times in order to get all 10 front page articles into separate articles. That creates a lot of actions and a lot of variables, and remember that every split creates variables you don’t need. As such, it’s wise to use local variables (lower case letters) for this type of work, as those won’t end up populating the Variables list in Tasker. I used global variables in the example, which can be smart if you need to refer to the resulting variables in other tasks and don’t want to copy them into global variables, but just be aware of the side effect and make a choice based on that.
I should point out that it’s possible to automate the process of splitting multiple variables multiple times, using Tasker’s For action, which essentially loops an action for each available specified variable or value. This is done by using arrays, which are essentially base variables with childs. The variable %Pocketables above is an array containing %Pocketables1, %Pocketables2, and so on. It is then possible to specify a set of actions that will run for each variable in an array, like for instance all children of %Pocketables. I won’t go into the use of arrays in more detail however, as it’ll further complicate an already complicated topic. My advise is to stick with the “manual method” until you’ve mastered it. Besides, unless you’re doing a ridiculous amount of variables, the “manual” way can often be easier to keep track of.
Also note that if you split into more than 10 parts, your second generation variables will start to be named the same as first generation variables. For instance, %Pocketables11 can be the 11th child of %Pocketables or it can be the 1st child of %Pocketables1. If the first generation %Pocketables11 is important, you don’t want the second generation %Pocketables11 overwriting it when it’s created.
Keeping track of all the child variables is often very hard, which is why you should play around with what splitter you use. It’s sometimes wiser to split multiple times in order to create lower numbered children instead of trying to cut as close as possible the first time around. Had you for instance been after only the title in the example above, ” title=” might have seemed like a good option for an initial splitter, since it immediately precedes the title. However, there are (at the time of this writing) 99 occurrences of that splitter in the source code for this site’s front page, which means that you would have to hunt around for which 10 of those 100 actually precedes a post title. You would then end up for for instance %Pocketables57 and %Pocketables71 as the relevant first generation children. Not only is this harder to deal with than a static naming scheme, but common splitters in web pages often vary in numbers as the page is updated, meaning that tomorrow it might split away something completely different. The naming scheme %Pocketables/2-11/2/1 created by the example method above, on the other hand, doesn’t have this problem.
Like I said, it’s a mess, which is why it’s not a bad idea to have a version of the text you’re splitting open on a computer while you’re working. That combined with CTRL + F to find text makes it so much easier to “cut the right spots.”
Variable Section
 Variable Split might be the most important tool available for this type of work, but it’s not the only tool. Another great one to know how to use is Variable Section, which is designed to pick a specific part of a variable and throw the rest out the virtual window. Unfortunately it doesn’t section based on splitters, like you wouldn’t be crazy to assume, but instead it sections based on character numbers.
Variable Split might be the most important tool available for this type of work, but it’s not the only tool. Another great one to know how to use is Variable Section, which is designed to pick a specific part of a variable and throw the rest out the virtual window. Unfortunately it doesn’t section based on splitters, like you wouldn’t be crazy to assume, but instead it sections based on character numbers.
The Variable Section configuration screen has five options to be aware of. The first is the Name, which is simply the name of the variable you want to section. The second is the character number you want to start at, for instance if you want to skip the first three letters in a variable, you choose 4 here. Length is the length from that character that you want to include in the sectioning, for instance choosing 5 here would just fit the word “apple.” Adapt to fit changes the previous option depending on the length of the variable, so you don’t try to section ten characters of a five character variable. Very useful if you don’t know the length of the section, just where it should start. Finally, Store Result In lets you save the result to a different variable than you started with.
So, what’s this feature for? Well, I find that it’s great for cutting off the beginning of variables that contain info they shouldn’t. Often this means variables that contain data you can’t split away because it’s different every time, or because the splitter you would have to use is so ridiculously common that it would somehow create issues.
For instance, let’s say you want to split the time (hours and minutes) out of a variable like this one:
13:30:52.000-04:00
Sure, you could split with a colon as the splitter, but that would also split the minutes from the hours. You could end up with variables in the form of %timesplit1, %timesplit2, and timespit3, which would be 13, 30, and 52.000-04, respectively. You could then reassemble the time by doing a Set Variable %timesplitx to %timesplit1:%timesplit2, and end up with a %timesplitx that is 13:30.
OR you could simply use Variable Section from 1 with length 5 and get a variable with 13:30 right away.
In many cases, Variable Section is an alternative to Variable Split, but it’s an alternative that can often save you a lot of work. Knowing that it’s there and when to use it can be very handy.
Variable Search Replace
 Variable Search Replace is a relatively new feature, and one I have mixed feelings about. In theory, it should replace Variable Split for a lot of tasks. In practice, it’s a feature that’s frankly still in beta.
Variable Search Replace is a relatively new feature, and one I have mixed feelings about. In theory, it should replace Variable Split for a lot of tasks. In practice, it’s a feature that’s frankly still in beta.
Problem 1 is that it doesn’t use Tasker simplified pattern matching system, it uses actual regular expressions. As such the method to use a wildcard isn’t * any more, it’s .* (note the period). If you’re used to pattern matching for If conditions, and don’t have experience from anything that uses actual regular expressions, this will make it that much more complicated to use.
Problem 2 is that it doesn’t support variables. If you type a variable into the field, it will use the variable name, not the variable content. According to the Tasker developer this has been on the todo list to fix for several months now, but it still isn’t fixed.
Bottom line, Variable Search Replace is a bit of an ugly duckling in the Tasker toolbox right now, one that is still a ways from turning into a beautiful swan. Because of this, I don’t want to spend too much time on it in this guide, but I will give you a quick example of how it can replace Variable Split in some cases.
In the Pocketables front page example above, we split out the URL by splitting multiple times. You could actually achieve the same by using Variable Search Replace and the following search string:
<h3><a href=.*”
This would search for any mention of <h3><a href=”, followed by the non Tasker-standard wildcard (.*), ending with a “. This would return results (separate variables for each match) along the lines of this:
<h3><a href=”http://pocketables.com/2012/09/tv-show-favs-for-android-hits-version-3-0.html“
The wildcard is here the URL, which we’ve “fenced in” by placing a wildcard in the string between two pieces that border it. We have to use <h3><a href=” here in order to catch the right URLs (not all the URLs in the code), and “ is needed to stop the wildcard from including absolutely everything following the URL. As such, we end up with some garbage information at the beginning and end. We can Variable Section from 1 length 13 to get rid of the beginning, but due to the varying length of the URL, we need to either Variable Search Replace or Variable Split the “ to get rid of that. So, you’re left with three actions anyways, meaning that it isn’t exactly infinitely superior to Variable Split. Personally I use Variable Split more or less exclusively, because at least I know where I have it with regards to pattern matching syntax and variable support.
Example 1: Weather forecast
Preperation
This is the how-to version of the weather forecast task found in this article. Since it was originally made as a download for people to use without understanding how it works, I’ll go through this example referring directly to the downloadable task. That way, you can download and import the task yourself, and “read along” as I explain the bits.
Download the task from below. Two versions are available, a direct .xml download and a zipped version. On some devices, you can go to this page in your browser, long click on the .xml download, select “save link”, open it once downloaded, and then select to open with Tasker. If that doesn’t work, download the .zip, and unzip it to the Tasker/tasks folder manually. The resulting steps are identical regardless of which of these methods you use.
Go into Tasker, long click on the Tasks tab, select Import. Select the Weather task.
Open the task, then the HTTP Get action. Switch out YYYYYYY in the Path field with your location. This can be a US zip code, State/City, or Country/City. Examples are 90210, CA/San_Francisco, and Norway/Hamar – with the slashes included. Then, switch out XXXXXXXXX with a Wunderground API key. You can get such a key for free by signing up for Wunderground: http://www.wunderground.com/weather/api/
This will not work without you obtaining your own API key. Random numbers or any of the examples used here won’t work in real life.
Make sure there are no spaces or other “irregularities” when you insert the API. The resulting Path field should look something like this:
api/123a123b123c/conditions/forecast/q/Norway/Hamar.xml
The bold text indicates the pieces you replaced.
Finally, go into the Say action, click on the magnifying glass next to Engine:Voice, and select a Text To Speech engine that you have installed.
Task download

Download: Weather.tsk.xml

Download: Weather.tsk.xml.zip
Explanation
Actions 1-2:
The weather data is available online in XML format, which we can get our hands on using HTTP Get. Like I explained earlier, I prefer doing HTTP Get into a local file and then read it into a variable using Read File rather than use the HTTP Get-generated variable %HTTPD. By the end of action 2, the result is that you have a variable %Weather that contains everything in the XML file.
Action 3:
This is the first Variable Split. At this point, you should have the XML file open in a full browser (or text editor) in order to be able to see what’s in it. If opening it in your browser brings up an RSS message, try using CTRL + U (show source) on the page.
The first splitter used here is <fcttext><
As you can see, the first forecast follows immediately after this splitter. This means that %Weather2 will contain the forecast plus a lot of garbage text, while %Weather1 is all the garbage text before the splitter.
That’s not all though. Since all the forecasts are “labeled” the same way, %Weather3, %Weather4 and so on will also be created. These contain weather data for future periods, similar to how %Weather2 is for the coming period. Again, %Weather1 is just garbage text.
Note: If you want the metric version instead of the imperial version of the forecast, use the splitter <fcttext_metric><![CDATA[. This will make it use units like km/h instead of mph. You can see the logic of this by studying the screenshot above.
Actions 4-5:
These are both Variable Split actions with ]]> as the splitter, one for %Weather2 and one for %Weather3. These simply cut off the garbage from the end of those variables, leaving you with the child variables %Weather21 and %Weather31 that contain the weather forecast and nothing else. This particular version of the task uses forecast information for two upcoming periods, which is why we’re cleaning up %Weather2 and %Weather3, but not %Weather4 and so on. If you want more periods, simply add more Variable Split actions like these for more %WeatherX variables, and use their %WeatherX1 children in the Say task at the end.
Actions 6-10:
Technically, you’re done getting the weather info after actions 4-5. You then have %Weather21 and %Weather31 which you can use however you like, be it in a Say action to give you a spoken forecast or perhaps to send to a Minimalistic Text widget to display somewhere. Actions 6-10 are however there to figure out if the second of the two upcoming forecasts is at night or in the morning. This is basically a fancy feature that isn’t strictly needed, but I added it originally to make the whole thing more “professional.” It also uses Variable Split, so I’ll explain how it works.
Action 6 copies the contents of %Weather2 into a new variable, %Nforecast. We’re going to split %Weather2 again using new splitters, and we don’t want to overwrite the existing child variables, so we’re making a copy in order to avoid this issue.
Action 7 is a Variable Split for %Nforecast with <title> as the splitter. Remember that %Weather2 (which %Nforecast is a copy of) is already a child, so it looks for the splitter in an already limited part of the original document. As such, there’s only one <title> in %Nforecast, even though there are many in the original source text. I’ve marked the parts that aren’t in %Nforecast with red below to demonstrate this.

Point being, this split results in a %Nforecast2 that contains the title of the second forecast period as well as a garbage </title> at the end.
Action 8 deletes this </title> by splitting %Nforecast2. This creates a %Nforecast21 which contains the title of the second forecast period.
Action 9 creates a variable %Nextforecast and sets it to “tomorrow.”
Action 10 overwrites the variable created in action 9 with the text “tonight” IF %Nforecast21 matches *night*/*Night*. This means that if the title of the second forecast period contains the word “night,” the value of %Nextforecast will be “tonight.” If it doesn’t contain that word, the value from action 9 (“tomorrow”) will stay.
At the end of these five actions, we have a variable that is either “tomorrow” or “tonight” depending on whether the second forecast period is the coming night or the next morning. If the forecast task is run early in the day, the first forecast period will be for that day, and the second will be for that night. If it’s run later in the day, the first forecast period will be that night, and the second the next morning. %Nextforecast lets us know which of those two are correct.
Action 11:
This is the Say action that actually gives us the spoken forecast. The text is:
Weather forecast for today is %Weather21. Weather forecast for %Nextforecast is %Weather31.
This Say text contains three variables. Two of them are the weather forecasts we got from the XML online, while the last, %Nextforecast, changes the text to correctly specify when the second forecast period is for.
Like I said though, you could easily skip actions 6-10. It only loses you the ability for the Say to correctly specify when the second forecast period is for, which might not matter to some – and likely not if you’re using this in a widget. It is however a good example because it uses data from the original XML source as an If condition, not just an information source. You could just as easily have used it in a Variable Value context, which has a lot of uses in situations where the variable in question isn’t just day/night.
Of course this example also extracted actual information, the weather forecast itself. The method is basically the same no matter what you do, you just have to know where to chop a source text up to get what you want.
Example 2: Local news fetcher
This example originates from a help request in our forums, where a forum member wanted to create a task that would fetch his local news and read it to him. The recipe is the same as I’ve already shown, but since this is a task I had to create from scratch, I fired up screen capture software on both my phone and PC and recorded what I was doing, while narrating. It should help visualize this entire article, as well as show a trick with using a Flash action as a “debug tool” when creating tasks like this. The video is below.
The website used as a source this time is this one. Checking the source for a bit revealed that the best splitter to start with is <h2>, which doesn’t immediately precede the headlines we’re after, but does have the advantage of not being used all over the place.
After splitting that first time we got variables %lbnews1, %lbnews2, %lbnews3 and so on, with %lbnews2 and beyond containing the headlines – along with some garbage text. Splitting %lbnews2 using the splitter ” > puts the headline at the beginning of the variable %lbnews22, but still leaves a bit of junk at the end. A final split of %lbnews22 using the splitter </a> leaves us with a variable %lbnews221 which contains only the headline, which can then be used directly in actions within the same task, or transferred to a global variable and used elsewhere.
Since the initial split created multiple children that share the same format as %lbnews2, just with a different article, we can then copy the actions that split %lbnews2 and %lbnews22, and simply replace the variables with %lbnews3 and %lbnews32, respectively. We then get %lbnews321, which contains the second headline – and nothing else. Copying again and doing the same with the number 4 would give us the third headline in %lbnews421, and so on and so forth for as many of the headlines you need. Each headline will then be in its own variable which can be used in a Say action or something else.
Like I said earlier, there are ways to automate this beyond manually copying the actions for each child, but for the sake of simplicity I won’t go into that.
Task download:
The downloads below contain the finished task with 5 complete headline variables. It can be edited to change the number of headlines it splits out of the source if necessary.
Follow the instructions for downloading and importing in example 1 to get this into Tasker. The final action, which is a Say, has to be edited to specify a different voice engine if the Amy UK English Ivona engine I’m using for my text to speech is not installed.

Download: Lpnews.tsk.xml

Download: Lpnews.tsk.xml.zip
Example 3: Google calendar event announcer
Another explanation of a task I’ve given you a download for before. This time it fetches data from Google Calender using Google Calendar’s ability to access the calendar with a web link, in XML format. Like with example 1, I’ll give you a task you can download and import, and then I’ll go through and explain how it works.
Preperation
Download the task from the bottom of the article. Four versions are available: A direct .xml download and a zipped version for each of the two basic task versions, DDMM and MMDD. Which of the basic versions you need depends on the date format you use. This task only works with the date formats DD/MM/YYYY and MM/DD/YYYY. This is a setting you pick in your device’s system settings, in the date and time section. It has to use one of those two, or it won’t work. If you read 07.12.2012 as July 12th, you want MM/DD/YYYY. If you read it as December 7th, you want DD/MM/YYYY.
Follow the instructions in example 1 on how to download and import the task.
Once imported, open the task, then the HTTP Get action. In the Path field, you will see XXXX and YYYY as part of the path:
calendar/feeds/XXXX%40gmail.
These are the two pieces of information you have to switch out. XXXX needs to be replaced with your Google user name, e.g. “example” if your login email for Google is [email protected]. If your email for Google does not end in @gmail.com, you also have to change the bit after %40 with whatever domaing your email is. Examples:
calendar/feeds/example%40gmail.
calendar/feeds/example%40googlemail.
YYYY needs to be replaced with a private access key for your Google calendar. To get this, start by going to the Google Calendar website, then go into settings. Click the Calendars tab, then the calendar you want to use. At the bottom of the calendar details screen, click the orange XML button next to Private Address. You should get a popup box with a URL that looks something like this:
https://www.google.com/calendar/feeds/example%40gmail.com/private-1234567812345678/basic
Your access key is the piece I highlighted in bold. You need to copy this in place of YYYY in the Path field in Tasker. An example of a finished Path would be:
calendar/feeds/example%40gmail.
Save the edit to the HTTP Get action and then find the Say action at the end. Select a speech engine that you have installed on your device.
Note: Recently created Google Calendar calendars use a different format with a [email protected] email in the URL. This task has been tested to work with the new format, however you need to grab both the specialized email address and the key from the XML button mentioned above.
Task download

Download (DDMM, .xml): CalendarDDMM.tsk.xml

Download (DDMM, .zip): CalendarDDMM.tsk.xml.zip

Download (MMDD, .xml): CalendarMMDD.tsk.xml

Download (MMDD, .zip): CalendarMMDD.tsk.xml.zip
Explanation
This task was made on demand for a very specific purpose: Reading the next upcoming event, if that’s on the same day. This means it won’t list multiple events, although you can use the same method (with a different source URL that contains the right data) to make one that does, if you need that.
Actions 1-2:
Reads the data into a variable, like before.
Action 3:
Copies the variable into another variable, since we’ll be splitting it multiple times. We did this earlier too, with another variable.
Action 4:
Does a variable split of %Ceventdate, which is the copy of the calendar source data, using startTime=’. This contains the start date and time of the event. This splits it right up against the edge of the time information, and because we’re working more with it later on, we don’t cut off anything from the end of it right now.
Action 5:
Copies the value of %Ceventdate2 into a new variable, %Eventdate. Like earlier, this is because we’re going to use this variable multiple times, and don’t want any overwrites.
Action 6:
This splits the recently created %Ceventdate2 copy %Eventdate using the splitter –. %Eventdate contains data in the form of 2012-09-12T21:30:00.000+02:00, which means that splitting by a dash puts the year in its own variable, the month in its own variable, and the day of the month plus some garbage text at the end in its own variable.
Action 7:
This splits %Eventdate3, which is the third child from action 6 (the one with the day of the month plus garbage) using the splitter T. This is purely to clean up that last variable from action 6, removing the garbage.
Action 8:
Creates a variable %Samedayevent and sets its value to “no.” This is to make sure that the default value of this variable is “no,” in case the If condition in action 9 isn’t met. We’ve done something similar before, and without this, a leftover value from the previous time the task ran will still be present if the If condition in action 9 isn’t met.
Action 9:
Overwrites the value of the variable created in action 8 to “yes” If %DATE matches %Eventdate31-%Eventdate2-%Eventdate1. This one requires a bit of explanation, and will make it clear what the previous bunch of actions were for.
%DATE is Tasker’s built-in variable for the date. It’s in a specific format, the same as the device’s system settings – hence why there are multiple versions of the task download based on the date format used. %Eventdate31-%Eventdate2-%Eventdate1 takes the day, month, and year that we got from actions 6-7 and rearranges them to match the format that %DATE is in. That way, we’re able to compare the current date (%DATE) with the date of the next event, even though they’re originally in different formats!
After action 9, we have a variable %Samedayevent that’s either “no” (if the If condition in 9 wasn’t met) or “yes” (if it was). This variable is a setting that we will use later to control whether or not the Say action mentions the next event. Note that like I said, this task was originally created for someone who wanted this specific feature. Many people would prefer that it lists the next event no matter if it’s not on the same day. It is however a great example of how you can process a mess of data into something that’s even in the same format that Tasker is used to.
Action 10:
With action 10, we’re done with the actions that check to see if the event is on the same day. Instead we’re back to dealing with our original variable, %Calendar. We made a copy of this in the beginning, which we then split out to eventually get the date of the event, and now we’re going to work with the original. In this case I don’t think it would have mattered if we hadn’t copied it to begin with, but it’s always good practice to do it to be sure.
Anyways, action 10 does a Variable Split of %Calendar with the splitter <title type=’text’>. This is the text that immediately precedes the title of the event, and even though it’s not unique (it’s used once earlier in the source text), it’s ok to use it this time because there will always only be one occurrence of that text before the one we want. That just means that instead of using the %Calendar2 child, we use %Calendar3.
Action 11:
Does a Variable Split of %Calendar3 with the splitter </title>. This is just for cleaning up the garbage text at the end of %Calendar3, a procedure we’ve used many times by now.
Action 12:
Splits the variable %Ceventdate2 with the splitter T. We haven’t used the %Ceventdate “family” for a few actions now, but it’s still there for us to use. This time we’re after the time, not the date, so we’re starting over. The reason why we copied %Ceventdate2 to a new variable in action 5 was to be able to use it now.
%Ceventdate2 is identical to the original %Eventdate, so its value starts with data in the format 2012-09-12T21:30:00.000+02:00 as well. I believe we could have used %Eventdate32 directly instead of starting from this far back with %Ceventdate2, but the original task was made in somewhat of a hurry, and I don’t want to change the task in this example compare to the original article where it was a download only. Keeping track of all these child variables is a pain, and sometimes you get them mixed up. It is however better to be safe than sorry.
Action 13:
A real world example of Variable Section! Sections %Ceventdate22, which now contains data in the format 21:30:00.000+02:00*garbage*, to only be 5 characters long. That means we get the hours, the colon, and the minutes – the time, in other words. This is where the original example of Variable Section above comes from, and like I mentioned then, it saves us from having to reassemble the time like we would have had to do had we split it with a colon (as the colon is used in the time, too).
Action 14-15:
These two actions set the variable %Nextevent to either “Your first appointment today is %Calendar31 at %Ceventdate22” or “You have no appointments scheduled for today”, depending on the value of %Samedayevent, which can be “yes” or “no.” These are frankly redundant as we could have put actions 8-9 here and have them do it directly, but again it has to do with this task being put together a bit too quickly.
Action 16:
The final action, the infamous Say which actually turns 15 actions worth of work into a spoken message. Simply tells us the value of %Nextevent, which was set in the two previous actions. The result is that it has a different message for a day without appointments, and of course the message is dynamic and has the title of the event (%Calendar31 from actions 10-11) and the time (%Ceventdate22 from actions 12-13).
This task is long, and complicated, because of the use of different messages for different situations (event/no event). Without that feature, it would have been a matter of splitting out the event title, which is fairly simple (actions 10-12, basically). It’s often the minor details that take time, as this example proves, and sometimes that extra hassle isn’t worth it for some people.
In conclusion
Being able to process data in variable using Tasker opens up for a lot of possibilities, but there’s also a lot to keep track of when you’re splitting variables left and right. Keeping a steady hand, having the source text open for reference, and debugging using a Flash action (see example 2) are essential for getting through this without going crazy in the process.
In the next part of the guide I’ll cover some tips and tricks of using Tasker, things that didn’t really feel natural including in any of the previous parts but still deserve to be mentioned. Later on in the series I’ll do parts dedicated to examples of all sorts, so if you have a profile or task you just can’t figure out how to make, let me know and it might make it into an article as an example, like example 2 in this article did.
